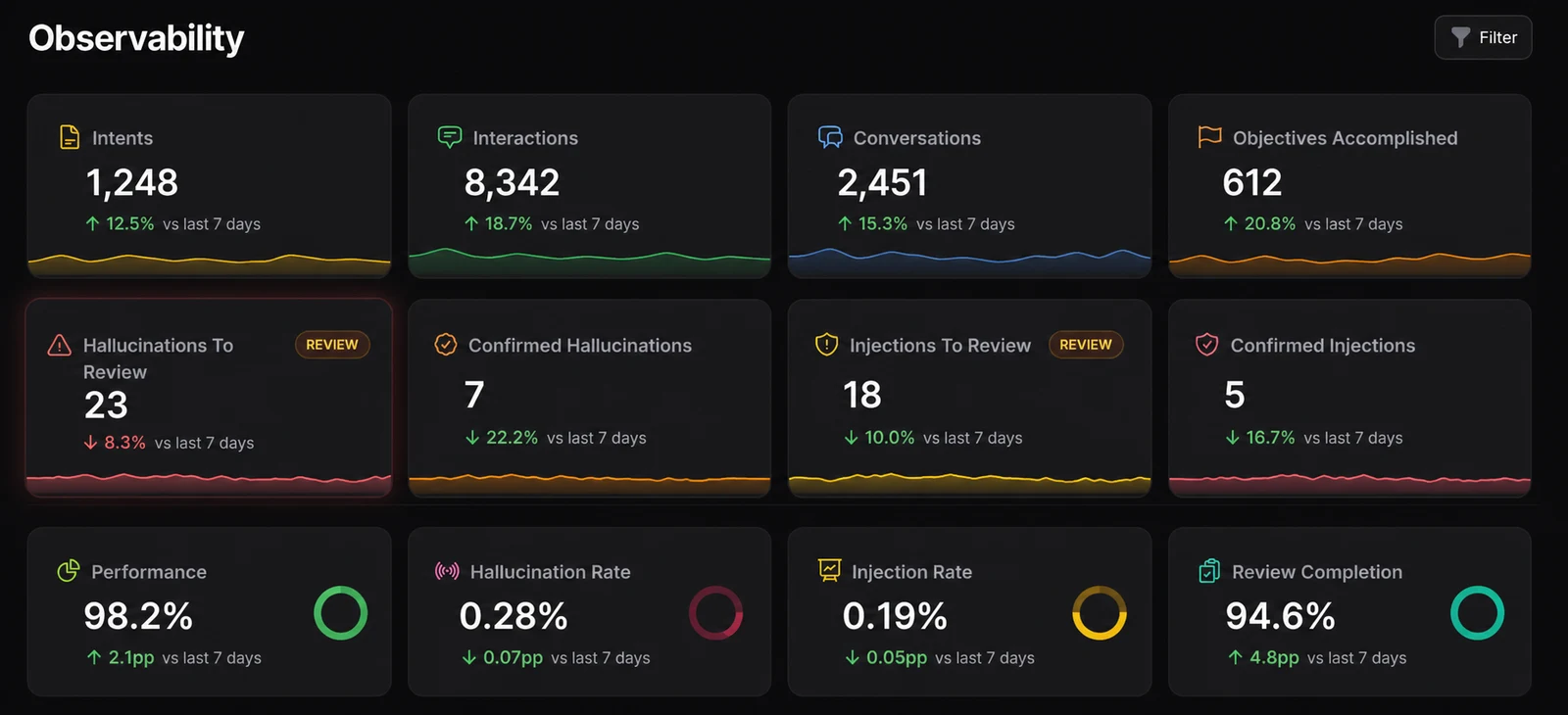
Les agents font de l’observabilité une exigence métier
Les équipes logicielles savent déjà pourquoi l’observabilité compte. Journaux, métriques, traces, alertes et procédures d’incident aident à comprendre si un système est sain et pourquoi quelque chose a changé. Les agents IA héritent de ce besoin, mais ils ajoutent un problème plus complexe : le système n’est plus seulement un logiciel déterministe.
Un agent peut recevoir deux fois la même requête et produire des sorties différentes. Il peut récupérer un contexte différent, appeler un outil différent, suivre un plan différent ou s’arrêter plus tôt que prévu. Une réponse techniquement réussie peut néanmoins être incorrecte, incomplète, trop coûteuse, trop lente ou inappropriée pour le processus métier qu’elle est censée soutenir.
C’est pourquoi l’observabilité des agents ne se réduit pas à la disponibilité. Un code 200 renvoyé par un endpoint LLM ne signifie pas que l’agent a fait le bon travail. En production, les équipes doivent savoir ce que l’agent a vu, ce qu’il a utilisé, ce qu’il a décidé, ce qu’il a modifié et si le résultat a créé de la valeur.
Les défaillances de l’IA surviennent souvent discrètement
Les applications traditionnelles échouent généralement de façons faciles à détecter : un service est hors service, une requête expire, un job plante ou un tableau de bord ne se charge plus. Les agents IA peuvent échouer plus silencieusement. Ils peuvent répondre avec assurance en s’appuyant sur des connaissances obsolètes. Ils peuvent omettre un appel d’outil important. Ils peuvent résumer un document de façon incorrecte. Ils peuvent produire une sortie qui semble plausible mais qui ne satisfait pas l’exigence opérationnelle.
Les erreurs discrètes sont particulièrement dangereuses lorsque les agents sont intégrés à des workflows réels. Dans un processus de support, l’agent peut orienter le dossier vers la mauvaise équipe. Dans un processus de documentation clinique, il peut omettre une preuve qui affecte le remboursement. Dans un workflow réglementaire, il peut ne pas préserver la traçabilité nécessaire pour une revue.
Le risque opérationnel ne vient pas seulement du fait que le modèle se trompe. Le risque, c’est que l’organisation ne voie pas où l’erreur est entrée dans le système.
La réponse finale n’est que la dernière étape
Beaucoup d’équipes commencent par surveiller la réponse finale : était-elle utile, factuelle, pertinente, sûre et conforme à la marque ? Ces vérifications sont nécessaires. Mais elles ne suffisent pas pour des agents en production parce que la réponse finale n’est que la partie visible d’un flux de travail plus long.
L’observabilité des agents doit suivre le processus depuis la source jusqu’à la sortie. Cela signifie tracer la requête utilisateur, l’intention détectée, la version du prompt, les connaissances récupérées, le modèle utilisé, les outils appelés, les permissions appliquées, la latence et le coût de chaque étape, la sortie finale et l’issue en aval.
Sans ce chemin complet, les équipes peuvent constater qu’une réponse est mauvaise sans savoir pourquoi. Le prompt était-il faible ? Les données sources étaient-elles incomplètes ? La recherche a-t-elle retourné le mauvais document ? Un outil a-t-il échoué silencieusement ? Le modèle était-il trop petit pour la tâche ? L’agent a-t-il choisi la mauvaise branche du processus ? L’observabilité transforme ces questions en preuves.
Ce que les équipes doivent surveiller
Les signaux exacts dépendent du cas d’usage, mais les agents en production ont généralement besoin de visibilité à plusieurs niveaux.
- Entrée et intention : ce que l’utilisateur ou le système a demandé, comment la requête a été classée et quel workflow a été déclenché.
- Contexte et récupération : quels documents, enregistrements, sites web, bases de données ou sources de connaissance internes ont été utilisés.
- Exécution du modèle et du prompt : versions de prompt, choix de modèle, paramètres, latence, coût, tentatives et erreurs.
- Activité des outils et systèmes : appels API, requêtes de base de données, actions navigateur, permissions, approbations et transferts de responsabilité.
- Qualité de la sortie : pertinence, factualité, exhaustivité, ton, conformité aux politiques et utilité pour le workflow.
- Résultat métier : l’agent a-t-il résolu la demande, réduit le travail manuel, amélioré la conversion, fait gagner du temps ou créé une valeur opérationnelle mesurable.
Les évaluations et le traçage sont la base
Deux capacités sont particulièrement importantes : les évaluations et le traçage.
Les évaluations aident les équipes à juger la qualité des sorties à grande échelle. Certaines vérifications sont déterministes, comme la présence d’un champ requis ou l’absence d’une affirmation interdite. D’autres utilisent des évaluations basées sur des modèles pour mesurer des dimensions telles que l’utilité, la pertinence, l’exhaustivité ou si la réponse est étayée par le contexte approuvé.
Le traçage explique comment une sortie a été produite. Une trace utile montre les étapes suivies par l’agent, les systèmes qu’il a touchés, le contexte récupéré, ainsi que le coût et la latence de chaque partie de l’exécution. Pour les équipes qui opèrent des processus réels, le traçage n’est pas qu’une fonctionnalité de débogage : c’est la manière dont elles examinent les incidents, répondent aux parties prenantes et améliorent le workflow dans le temps.
L’observabilité doit couvrir les données, le code, les systèmes et les modèles
Une erreur courante consiste à considérer l’observabilité comme quelque chose qui commence et s’arrête à la frontière du modèle. En pratique, de nombreux problèmes qui ressemblent à des défauts de modèle sont causés en amont ou en aval.
Les données sources peuvent être obsolètes. Un document peut avoir été indexé incorrectement. Un changement de prompt peut avoir réduit les performances pour un segment d’utilisateurs spécifique. Un outil peut retourner des résultats partiels. Une règle de permission peut être trop large ou trop restrictive. Le modèle peut bien fonctionner, mais le workflow environnant peut être défaillant.
Des opérations d’IA fiables exigent une visibilité sur l’ensemble du système : la couche de données, la couche applicative, la couche de prompt et de code, les outils connectés et la couche modèle. Les agents sont des systèmes de systèmes. L’observabilité doit refléter cette réalité.
L’objectif n’est pas les tableaux de bord. L’objectif est le contrôle.
La surveillance n’est utile que si les équipes peuvent agir sur ce qu’elles observent. Un tableau de bord qui montre un taux d’erreur en hausse, un coût plus élevé ou une baisse du score d’évaluation est un point de départ. La vraie valeur vient de la capacité à résoudre l’incident.
Cela peut signifier modifier un prompt, remplacer une source de connaissance, désactiver un outil, resserrer des permissions, ajouter une étape de revue humaine, basculer un workflow vers un autre modèle ou créer une nouvelle évaluation pour un mode de défaillance qui n’était pas visible auparavant.
C’est là que l’observabilité devient opérationnelle. Elle offre aux équipes une boucle de rétroaction : observer ce qui s’est passé, comprendre pourquoi, changer le système et mesurer si le changement a amélioré le processus.
Comment commencer
Les équipes n’ont pas besoin d’instrumenter tout dès le premier jour. Mais elles doivent commencer par les signaux qui correspondent au risque du processus. Un assistant public pour un site web peut débuter par la qualité des réponses, les questions sans réponse, le coût et la conversion. Un agent d’opérations interne peut nécessiter des traces d’outils, des permissions, des approbations et la complétion des tâches. Un workflow réglementé peut demander l’historique des preuves, le versioning et des pistes d’audit dès le départ.
L’important est de concevoir l’observabilité avant que l’agent ne devienne critique. Les pilotes peuvent survivre avec une revue manuelle et un débogage ad hoc. Les workflows en production, non. Une fois que de vrais utilisateurs, de vraies données et de vraies décisions métier sont en jeu, la question n’est plus de savoir si l’agent peut produire une bonne démo, mais si l’organisation peut l’exploiter de manière responsable.
Les agents IA deviendront plus utiles à mesure qu’ils auront accès à davantage de contexte et d’outils. Cela les rend aussi plus difficiles à comprendre sans la bonne visibilité. L’observabilité est la façon dont les équipes maintiennent ce pouvoir utilisable, mesurable et sous contrôle.