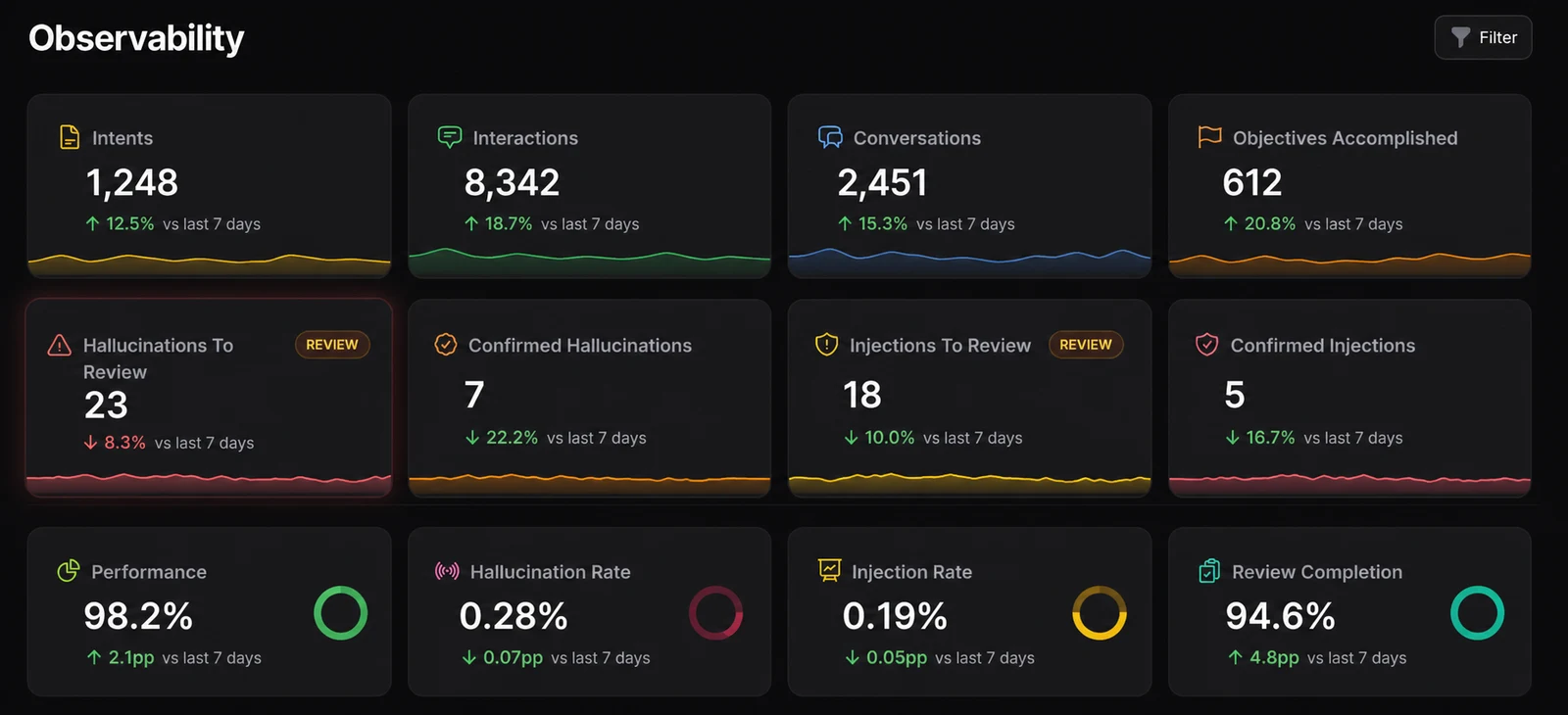
Agentes tornam a observabilidade um requisito empresarial
Equipes de software já entendem por que a observabilidade é importante. Logs, métricas, traces, alertas e fluxos de trabalho de incidentes ajudam as equipes a entender se um sistema está saudável e por que algo mudou. Agentes de IA herdam essa necessidade, mas acrescentam um problema mais complexo: o sistema não é mais apenas software determinístico.
Um agente pode receber a mesma solicitação duas vezes e produzir saídas diferentes. Pode recuperar contexto distinto, chamar uma ferramenta diferente, seguir um plano diverso ou parar antes do esperado. Uma resposta tecnicamente bem‑sucedida ainda pode estar errada, incompleta, ser cara demais, lenta demais ou inadequada para o processo de negócio que deveria suportar.
Por isso a observabilidade de agentes não pode ser reduzida a disponibilidade. Uma resposta 200 de um endpoint de LLM não significa que o agente fez o trabalho correto. Equipes em produção precisam saber o que o agente viu, o que usou, o que decidiu, o que alterou e se o resultado gerou valor.
Falhas de IA muitas vezes acontecem silenciosamente
Aplicações tradicionais geralmente falham de formas fáceis de detectar: um serviço cai, uma requisição expira, um job trava ou um dashboard deixa de carregar. Agentes de IA podem falhar de maneira mais silenciosa. Podem responder com confiança usando conhecimento obsoleto. Podem pular uma chamada de ferramenta importante. Podem resumir um documento incorretamente. Podem gerar uma saída que parece plausível, mas que não atende ao requisito operacional.
Falhas silenciosas são especialmente perigosas quando os agentes estão conectados a fluxos de trabalho reais. Em um processo de suporte, o agente pode direcionar o caso para o time errado. Em um processo de documentação clínica, pode deixar de identificar evidências que afetam o reembolso. Em um fluxo regulatório, pode não preservar a rastreabilidade necessária para revisão.
O risco operacional não é apenas que o modelo esteja errado. O risco é que a organização não consiga ver onde a incorreção entrou no sistema.
A resposta final é apenas a última etapa
Muitas equipes começam monitorando a resposta final: foi útil, factual, relevante, segura e alinhada à marca? Essas verificações importam. Mas não são suficientes para agentes em produção, porque a resposta final é apenas a ponta visível de um fluxo de trabalho mais longo.
A observabilidade de agentes precisa seguir o processo desde a origem até a saída. Isso significa rastrear a solicitação do usuário, a intenção detectada, a versão do prompt, o conhecimento recuperado, o modelo usado, as ferramentas chamadas, as permissões aplicadas, a latência e o custo de cada etapa, a saída final e o resultado a jusante.
Sem esse caminho completo, as equipes podem ver que uma resposta foi ruim e ainda assim não saber por quê. O prompt era fraco? A fonte de dados estava incompleta? A recuperação devolveu o documento errado? Uma ferramenta falhou silenciosamente? O modelo era pequeno demais para a tarefa? O agente escolheu o ramo errado do processo? Observabilidade é o que transforma essas perguntas em evidência.
O que as equipes devem observar
Os sinais exatos dependem do caso de uso, mas agentes em produção geralmente precisam de visibilidade em várias camadas.
- Entrada e intenção: o que o usuário ou sistema solicitou, como a requisição foi classificada e qual fluxo de trabalho foi acionado.
- Contexto e recuperação: quais documentos, registros, sites, bases de dados ou fontes de conhecimento internas foram usados.
- Execução de modelo e prompt: versões de prompt, escolhas de modelo, parâmetros, latência, custo, tentativas e erros.
- Atividade de ferramentas e sistemas: chamadas de API, consultas a bancos, ações de navegador, permissões, aprovações e transferências de responsabilidade.
- Qualidade da saída: relevância, factualidade, completude, tom, conformidade com políticas e utilidade para o fluxo de trabalho.
- Resultado de negócio: se o agente resolveu a solicitação, reduziu trabalho manual, melhorou conversão, economizou tempo ou criou valor operacional mensurável.
Avaliações e rastreamento são a base
Duas capacidades são especialmente importantes: avaliações e rastreamento.
Avaliações ajudam equipes a julgar a qualidade das saídas em escala. Algumas verificações são determinísticas, como se um campo obrigatório está presente ou se uma resposta inclui uma afirmação proibida. Outras usam avaliação baseada em modelos para aferir dimensões como utilidade, relevância, completude ou se a resposta está fundamentada no contexto aprovado.
Rastreamento explica como uma saída aconteceu. Um trace útil mostra os passos que o agente seguiu, os sistemas que tocou, o contexto que recuperou e o custo e a latência de cada parte da execução. Para equipes que operam processos reais, o rastreamento não é só uma funcionalidade de depuração. É como revisam incidentes, respondem a partes interessadas e melhoram o fluxo de trabalho ao longo do tempo.
A observabilidade deve incluir dados, código, sistemas e modelos
Um erro comum é tratar observabilidade como algo que começa e termina na fronteira do modelo. Na prática, muitos problemas que parecem ser do modelo têm causa a montante ou jusante.
Os dados de origem podem estar desatualizados. Um documento pode ter sido indexado incorretamente. Uma mudança no prompt pode ter reduzido a performance para um segmento específico de usuários. Uma ferramenta pode estar retornando resultados parciais. Uma regra de permissão pode ser ampla demais ou excessivamente restritiva. O modelo pode estar performando bem, mas o fluxo de trabalho ao redor pode ser frágil.
Operações confiáveis de IA exigem visibilidade por todo o sistema: camada de dados, camada de aplicação, camada de prompts e código, ferramentas conectadas e camada de modelos. Agentes são sistemas de sistemas. A observabilidade precisa corresponder a essa realidade.
O objetivo não são dashboards. O objetivo é o controle.
Monitorar é útil apenas se as equipes puderem agir com base no que aprendem. Um dashboard que mostra aumento de erros, custo mais alto ou queda na pontuação de avaliação é um ponto de partida. O valor real vem de conseguir resolver o incidente.
Isso pode significar mudar um prompt, substituir uma fonte de conhecimento, desabilitar uma ferramenta, restringir permissões, adicionar uma etapa de revisão humana, migrar um fluxo de trabalho para outro modelo ou criar uma nova avaliação para um modo de falha que antes não era visível.
É aí que a observabilidade se torna operacional. Ela dá às equipes um ciclo de feedback: observe o que aconteceu, entenda por que aconteceu, altere o sistema e meça se a mudança melhorou o processo.
Como começar
As equipes não precisam instrumentar tudo no primeiro dia. Mas devem começar pelos sinais que correspondem ao risco do processo. Um assistente público de site pode começar pela qualidade das respostas, perguntas sem resposta, custo e conversão. Um agente de operações internas pode precisar de traces de ferramentas, permissões, aprovações e conclusão de tarefas. Um fluxo regulado pode precisar desde o início de histórico de evidências, versionamento e trilhas de revisão.
O movimento importante é projetar a observabilidade antes que o agente se torne crítico. Pilotos sobrevivem com revisão manual e depuração ad hoc. Fluxos de trabalho de produção não. Quando há usuários reais, dados reais e decisões de negócio reais envolvidas, a questão não é mais se o agente consegue produzir uma boa demonstração. A questão é se a organização consegue operá‑lo de forma responsável.
Agentes de IA se tornarão mais úteis à medida que ganharem acesso a mais contexto e mais ferramentas. Isso também os torna mais difíceis de entender sem a visibilidade correta. Observabilidade é como as equipes mantêm esse poder utilizável, mensurável e sob controle.