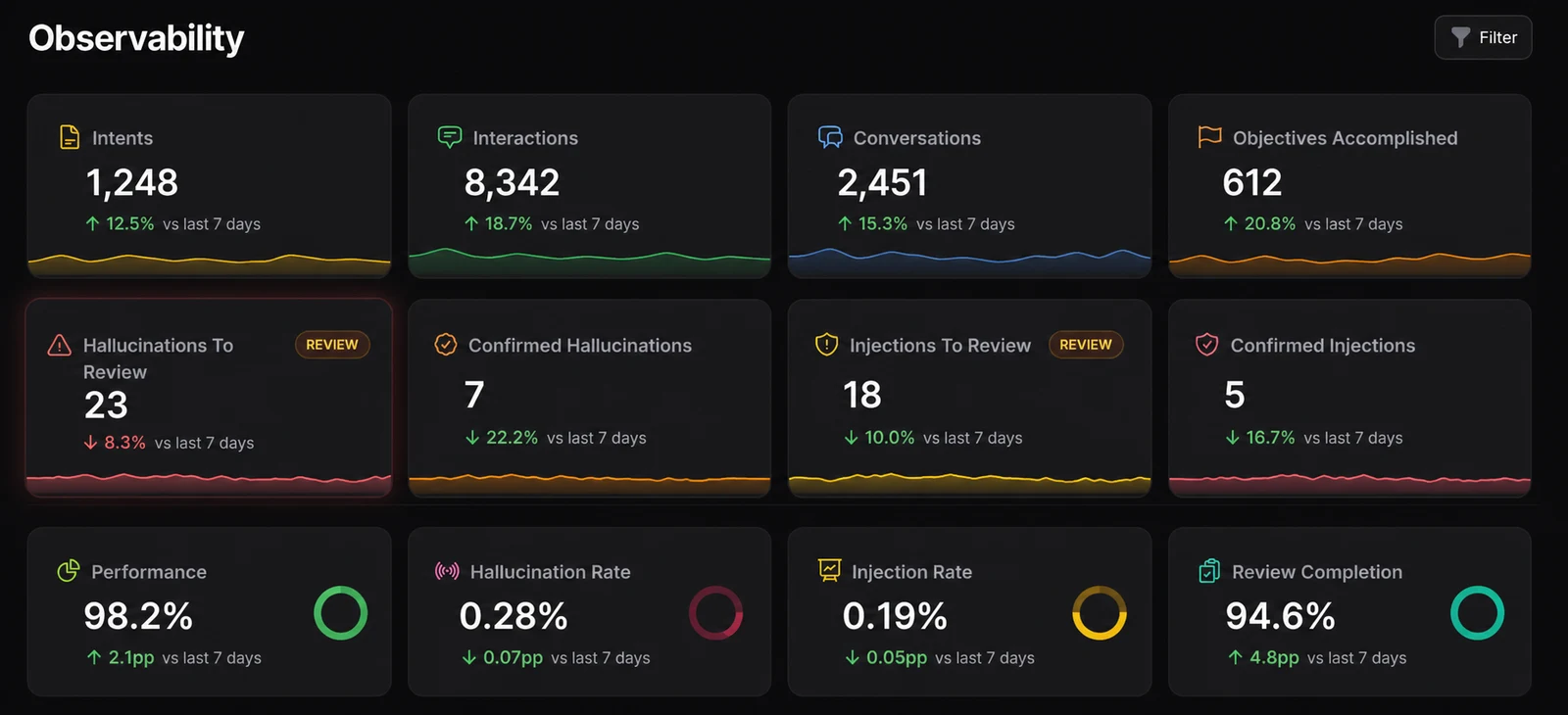
Los agentes convierten la observabilidad en un requisito empresarial
Los equipos de software ya entienden por qué la observabilidad importa. Logs, métricas, traces, alertas y flujos de trabajo de incidentes ayudan a saber si un sistema está sano y por qué algo cambió. Los agentes de IA heredan esa necesidad, pero añaden un problema más difícil: el sistema deja de ser solo software determinista.
Un agente puede recibir la misma petición dos veces y producir salidas distintas. Puede recuperar distinto contexto, llamar a una herramienta diferente, seguir un plan distinto o detenerse antes de lo esperado. Una respuesta técnicamente exitosa puede seguir siendo errónea, incompleta, demasiado costosa, demasiado lenta o inapropiada para el proceso de negocio que debe soportar.
Por eso la observabilidad de agentes no puede reducirse al tiempo de actividad. Un 200 de un endpoint LLM no significa que el agente haya hecho el trabajo correcto. Los equipos en producción necesitan saber qué vio el agente, qué usó, qué decidió, qué cambió y si el resultado creó valor.
Las fallas de la IA suelen ocurrir en silencio
Las aplicaciones tradicionales normalmente fallan de formas fáciles de detectar: un servicio cae, una petición agota el tiempo, un job se bloquea o un tablero deja de cargarse. Los agentes de IA pueden fallar más silenciosamente. Pueden responder con confianza usando conocimiento obsoleto. Pueden omitir una llamada a una herramienta importante. Pueden resumir mal un documento. Pueden generar una salida que parece plausible pero que no satisface el requisito operativo.
Las fallas silenciosas son especialmente peligrosas cuando los agentes están conectados a flujos de trabajo reales. En un proceso de soporte, el agente podría derivar el caso al equipo equivocado. En documentación clínica, podría omitir evidencia que afecta el reembolso. En un flujo regulatorio, podría no preservar la trazabilidad necesaria para la revisión.
El riesgo operacional no es solo que el modelo esté equivocado. El riesgo es que la organización no pueda ver por dónde se introdujo el error en el sistema.
La respuesta final es solo la última milla
Muchos equipos comienzan monitorizando la respuesta final: ¿fue útil, veraz, relevante, segura y alineada con la marca? Esos controles importan. Pero no bastan para agentes en producción porque la respuesta final es solo el extremo visible de un flujo de trabajo más largo.
La observabilidad de agentes debe seguir el proceso desde la fuente hasta la salida. Eso significa rastrear la petición del usuario, la intención detectada, la versión del prompt, el conocimiento recuperado, el modelo usado, las herramientas llamadas, los permisos aplicados, la latencia y el coste de cada paso, la salida final y el resultado descendente.
Sin ese camino completo, los equipos pueden ver que una respuesta fue pobre pero seguir sin saber por qué. ¿El prompt era débil? ¿Los datos fuente estaban incompletos? ¿La recuperación devolvió el documento equivocado? ¿Una herramienta falló silenciosamente? ¿El modelo era demasiado pequeño para la tarea? ¿El agente eligió la rama equivocada del proceso? La observabilidad es lo que convierte esas preguntas en evidencia.
Qué deberían observar los equipos
Las señales exactas dependen del caso de uso, pero los agentes en producción suelen necesitar visibilidad en varias capas.
- Entrada e intención: qué pidió el usuario o el sistema, cómo se clasificó la solicitud y qué flujo de trabajo se activó.
- Contexto y recuperación: qué documentos, registros, sitios web, bases de datos o fuentes de conocimiento internas se usaron.
- Modelo y ejecución del prompt: versiones del prompt, elección de modelos, parámetros, latencia, costes, reintentos y errores.
- Actividad de herramientas y sistemas: llamadas a APIs, consultas a bases de datos, acciones en navegador, permisos, aprobaciones y transferencias.
- Calidad de la salida: relevancia, factualidad, completitud, tono, cumplimiento de políticas y utilidad para el flujo de trabajo.
- Resultado comercial: si el agente resolvió la solicitud, redujo trabajo manual, mejoró la conversión, ahorró tiempo o generó valor operativo medible.
Evaluaciones y trazabilidad son la base
Dos capacidades son especialmente importantes: las evaluaciones y la trazabilidad.
Las evaluaciones ayudan a los equipos a juzgar la calidad de las salidas a escala. Algunas comprobaciones son deterministas, como si está presente un campo obligatorio o si una respuesta incluye una afirmación prohibida. Otras utilizan evaluación basada en modelo para valorar dimensiones como utilidad, relevancia, completitud o si la respuesta está fundamentada en el contexto aprobado.
La trazabilidad explica cómo se produjo una salida. Una traza útil muestra los pasos que siguió el agente, los sistemas que tocó, el contexto que recuperó y el coste y la latencia de cada parte de la ejecución. Para los equipos que operan procesos reales, la trazabilidad no es solo una función de depuración. Es la forma en que revisan incidentes, responden a consultas de las partes interesadas y mejoran el flujo de trabajo con el tiempo.
La observabilidad debe incluir datos, código, sistemas y modelos
Un error común es tratar la observabilidad como algo que empieza y termina en el límite del modelo. En la práctica, muchos problemas que parecen ser del modelo son causados aguas arriba o aguas abajo.
Los datos fuente pueden estar obsoletos. Un documento puede haberse indexado incorrectamente. Un cambio en el prompt puede haber reducido el rendimiento para un segmento de usuarios específico. Una herramienta puede estar devolviendo resultados parciales. Una regla de permisos puede ser demasiado amplia o demasiado restrictiva. El modelo puede estar rindiendo bien, pero el flujo de trabajo circundante puede ser débil.
Las operaciones de IA fiables requieren visibilidad en todo el sistema: la capa de datos, la capa de aplicación, la capa de prompts y código, las herramientas conectadas y la capa de modelos. Los agentes son sistemas de sistemas. La observabilidad debe reflejar esa realidad.
El objetivo no son los paneles de control. El objetivo es el control.
La monitorización solo es útil si los equipos pueden actuar sobre lo que aprenden. Un panel que muestra una tasa de errores en aumento, un coste más alto o una puntuación de evaluación baja es un punto de partida. El valor real proviene de poder resolver el incidente.
Eso puede significar cambiar un prompt, reemplazar una fuente de conocimiento, deshabilitar una herramienta, restringir permisos, añadir una revisión humana, mover un flujo de trabajo a otro modelo o crear una nueva evaluación para un modo de fallo que antes no era visible.
Aquí es donde la observabilidad se vuelve operativa. Proporciona a los equipos un bucle de retroalimentación: observa lo que pasó, entiende por qué pasó, cambia el sistema y mide si el cambio mejoró el proceso.
Cómo empezar
Los equipos no necesitan instrumentarlo todo desde el día uno. Pero deberían comenzar por las señales que coincidan con el riesgo del proceso. Un asistente público de sitio web puede empezar por la calidad de las respuestas, las preguntas sin responder, el coste y la conversión. Un agente de operaciones internas puede necesitar trazas de herramientas, permisos, aprobaciones y finalización de tareas. Un flujo regulado puede requerir historial de evidencias, versionado y pistas de revisión desde el principio.
El movimiento importante es diseñar la observabilidad antes de que el agente se vuelva crítico. Los proyectos piloto pueden sobrevivir con revisión manual y depuración ad hoc. Los flujos de trabajo en producción no. Una vez que hay usuarios reales, datos reales y decisiones de negocio reales, la pregunta deja de ser si el agente puede producir una buena demostración. La pregunta es si la organización puede operarlo de forma responsable.
Los agentes de IA serán más útiles a medida que ganen acceso a más contexto y más herramientas. Eso también los hace más difíciles de entender sin la visibilidad adecuada. La observabilidad es la forma en que los equipos mantienen ese poder utilizable, medible y bajo control.